Introduction
In the Spring Semester of 2023 we embarked, with Romain Birling, on a mini-project as part of the Artificial Neural Networks/Reinforcement Learning course at EPFL. Our focus was on Deep Q-learning for Epidemic Mitigation, aiming to study the impact of different policies on epidemic control.
Unmitigated Epidemic Analysis
Initially, we analyzed an unmitigated epidemic model, observing rapid decreases in susceptible populations and corresponding increases in recoveries and deaths. This highlighted the dire consequences of uncontrolled spread, with significant fatalities occurring in a short period.
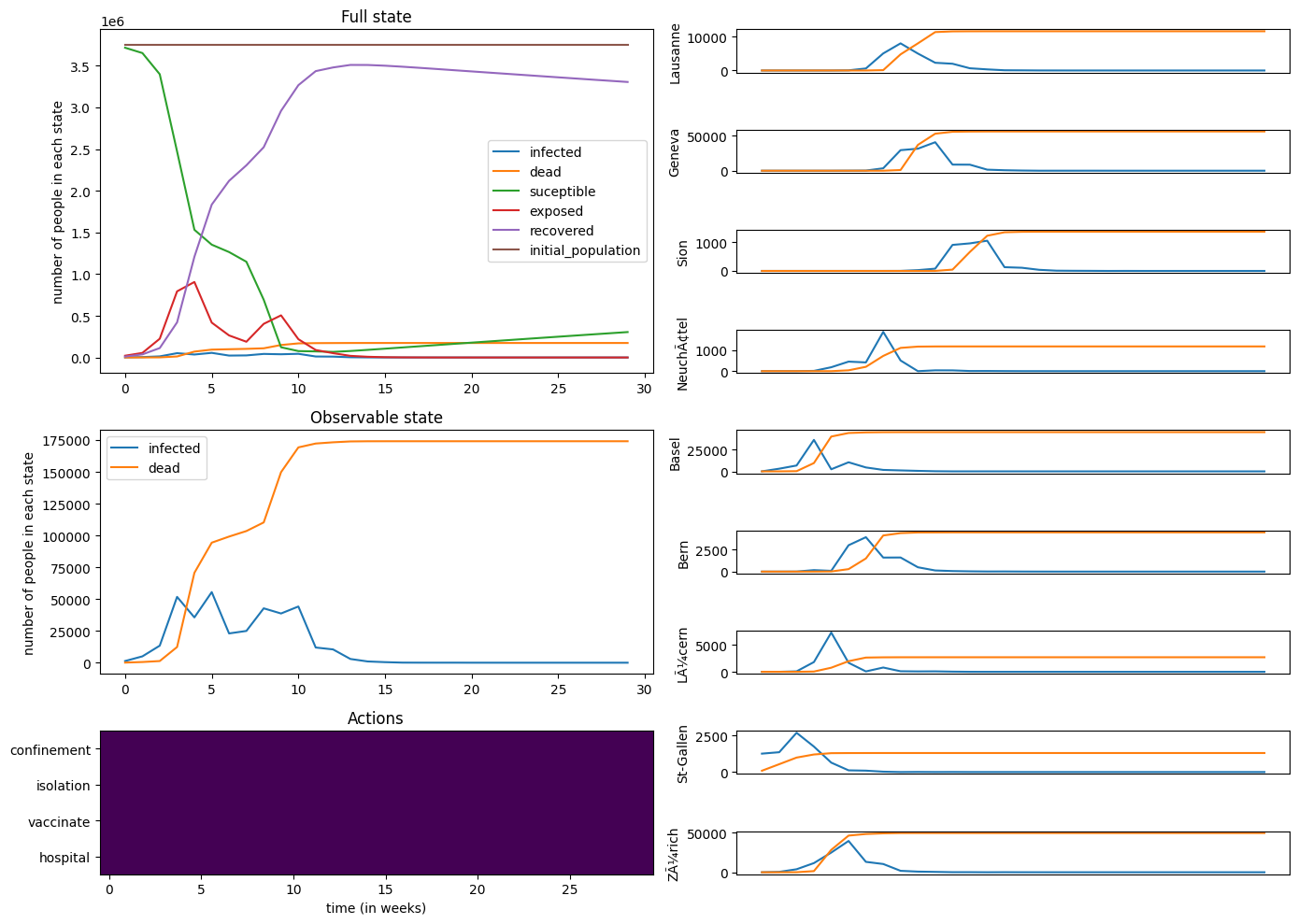
Professor Russo’s Policy
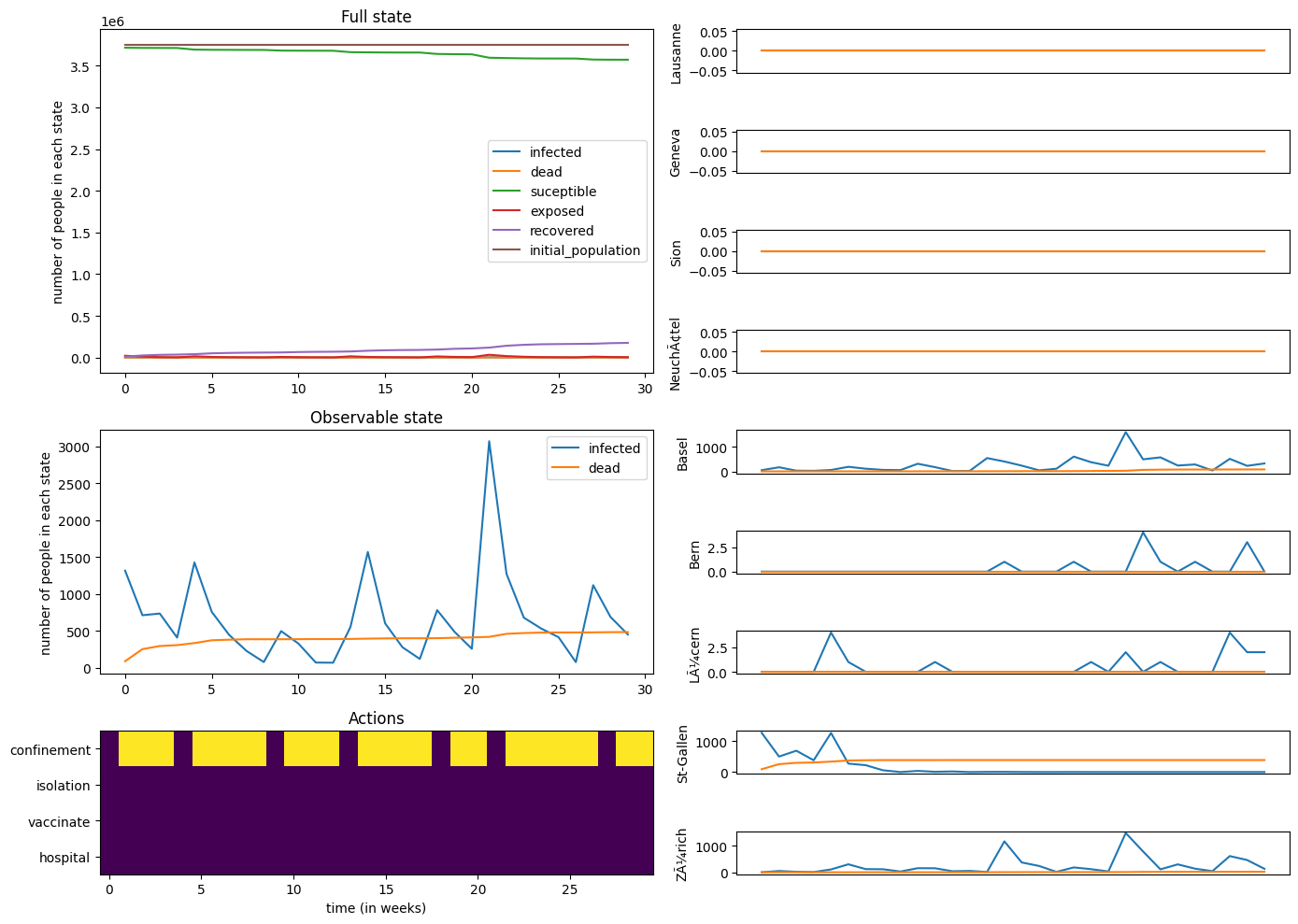
We then implemented Professor Russo’s policy, which involved periodic confinements triggered by infection thresholds. This policy showed a stabilizing effect on susceptible populations and reduced fatalities, although it did not completely halt the epidemic within 30 weeks.
Deep Q-Learning Approaches
Binary Action Space
Our first approach involved Deep Q-Learning with a binary action space. The policy learned through this method, however, did not outperform Professor Russo’s policy, indicating the complexity of epidemic control through confinement strategies.
Decreasing Exploration
We then experimented with a decreasing exploration strategy in Deep Q-Learning. This approach resulted in a policy that significantly reduced the average death count, despite having higher average confinement days, demonstrating a more effective control of the epidemic.
More Complex Action Spaces
Exploring further, we designed a toggle-action space to manage a multi-action policy, attempting to handle actions without expanding the action space excessively. However, this approach did not yield a successful learning outcome, as the policy tended to avoid taking any actions.
Factorized Q-values
Our final exploration was with factorized Q-values for a multi-action agent. This approach showed a slight improvement over the toggle-action policy but still faced challenges in outperforming the binary-action-space policy.
Conclusion
Our project demonstrated the potential and limitations of Deep Q-Learning in epidemic mitigation. While certain strategies showed promise in reducing fatalities, the complexity of epidemic dynamics poses significant challenges for reinforcement learning models. This exploration contributes to the broader understanding of AI applications in public health crises.
Explore the project on GitHub: